什么是爬虫
以下定义来自百度百科
网络爬虫(又被称为网页蜘蛛,网络机器人,在
FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。 通俗的来讲,爬虫就是使用机器语言来辅助人工查阅的一种技术形式.
爬虫的分类
网络爬虫按照系统结构和实现技术,大致可以分为以下几种类型,实际的网络爬虫系统通常是几种爬虫技术相结合实现的
通用网络爬虫(General Purpose Web Crawler)
通过一个url进行扩充到整个web,主要为门户站点搜索引擎和大型Web服务提供商采集数据.适用于为搜索引擎搜索广泛的主题,有较强的应用价值.
通用网络爬虫的结构大致可以分为页面爬行模块、页面分析模块、链接过滤模块、页面数据库、URL队列、初始URL集合几个部分。
聚焦网络爬虫(Focused Web Crawler)
指选择性地爬行那些与预先定义好的主题相关页面的网络爬虫,和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求.
增量式网络爬虫(Incremental Web Crawler)
指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在一定程度上保证所爬行的页面是尽可能新的页面
深层网络爬虫(Deep Web Crawler)
指那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,或需要授权的资源,只有用户提交一些关键词才能获得的Web页面
爬虫抓取策略
深度优先策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。
宽度优先策略
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取 URL 队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。
非完全PageRank策略(Partial PageRank)
PartialPageRank算法借鉴了PageRank算法的思想:
对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,在此集合内计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的网页按照PageRank值的大小排列,并按照该顺序抓取页面。
如果每次抓取一个页面,就重新计算PageRank值,一种折中方案是:每抓取K个页面后,重新计算一次PageRank值。
但是这种情况还会有一个问题:对于已经下载下来的页面中分析出的链接,也就是我们之前提到的未知网页那一部分,暂时是没有PageRank值的。
为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有入链传递进来的PageRank值进行汇总,这样就形成了该未知页面的PageRank值,从而参与排序。
OPIC策略(OnlinePage Importance Computation)
OPIC的字面含义是“在线页面重要性计算”,该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。
当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。
对于待抓取URL队列中的所有页面,则按照拥有的现金数进行排序,优先下载“现金”最充裕的网页。
大站优先策略
以网站为单位衡量网页的重要性,对于待抓取URL队列中的所有网页,根据所属的网站进行分类。如果哪个网站待下载页的页面数最多,则优先下载这些链接。其本质是倾向于优先下载大型网站。
爬虫的意义
通过技术手段减少人工成本
应用场景
- 批量自动化 搜索引擎的数据来源,基本上都来自于爬虫.抢票软件也是爬虫的一种应用.
- 数据分析与挖掘 分析用户信息,进行用户画像(跟踪抓取个人信息进行综合化处理),挖掘有商业价值的信息(征信信息,各种门票车票代购)
爬虫的危害
技术是一把双刃剑,可以说互联网的流量一半以上自于爬虫.

以上统计引用自2018上半年互联网恶意爬虫分析
爬虫解决了海量数据的查询归纳,但是爬虫的危害也随之而来,不遵守规则的爬虫泄露隐私信息,无脑抓取的爬虫给网站带来巨大压力等等.
综合的来说,合理的使用爬虫是每个人都应该遵守的规则,技术应当为人谋利,而不应当损害人的利益.
爬虫的防与攻
防
- 添加
Robots协议 可以限制遵守规则的爬虫,对于不遵守规则的则需要通过收集证据走法律途径. - 反爬虫
- 前端混淆,如自定义字符集,错位显示,关键信息图片化
- 登录:资源需要登录后访问+封号
- 防刷:限制访问频率+验证码
- 行为识别:识别是否有生物特征,如鼠标轨迹,网络环境等
- 蜜罐:表单设置隐藏参数提交陷阱
- 投毒:对于判定是爬虫的访问源,返回假数据
攻
- 使用
ip代理解决频率限制 - 使用僵尸帐号作为登录池
- 验证码自动识别+人工打码+验证码爆破
- 手机端群控
- 自动化测试工具模拟真实浏览器,如
Selenium
防的难点
越具有商业价值的信息,防护的越强,特别是一些技术形/依靠信息服务的公司. 难点在于防守受限于访问来源识别的准确性,要保证真实的用户可以正常访问,减少误杀的情况.
攻的难点
- 需要登录抓取的资源,帐号资源成本
- 代理ip资源成本
- 网站承受能力不一,需要合理调整抓取频率
总结
防守与爬虫攻击是一个堆技术堆投入的过程.
怎样开发爬虫
爬虫需要学习的技能点
- 网络请求数据分析
- 请求代理抓包
- 浏览器控制台的使用
html标签ajax请求json,xml数据- …
- 数据提取与过滤
- 正则表达式
css标签选择器xpath表达式
- 防反爬虫
-
附:常见
http请求头标识header example value remark Accept*/* Accept-Encodinggzip, deflate, br Accept-Languagezh-CN,zh;q=0.9,en;q=0.8 Cache-Controlno-cache Connectionkeep-alive Cookieuid=123456 Hostexample.com Pragmano-cache Refererhttps://www.baidu.com/ User-AgentMozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
使用java开发爬虫对应的工具
- 模拟
http请求-httpcomponents-client - 解析
html/xml文档-jsoup、dom4j - 爬虫框架-webmagic(简单易用,着重介绍)
- 其他爬虫框架-各大主流编程语言-常用爬虫框架以及优劣分析
java爬虫框架-webmagic基本介绍
- 文档地址:webmagic
- 整体架构
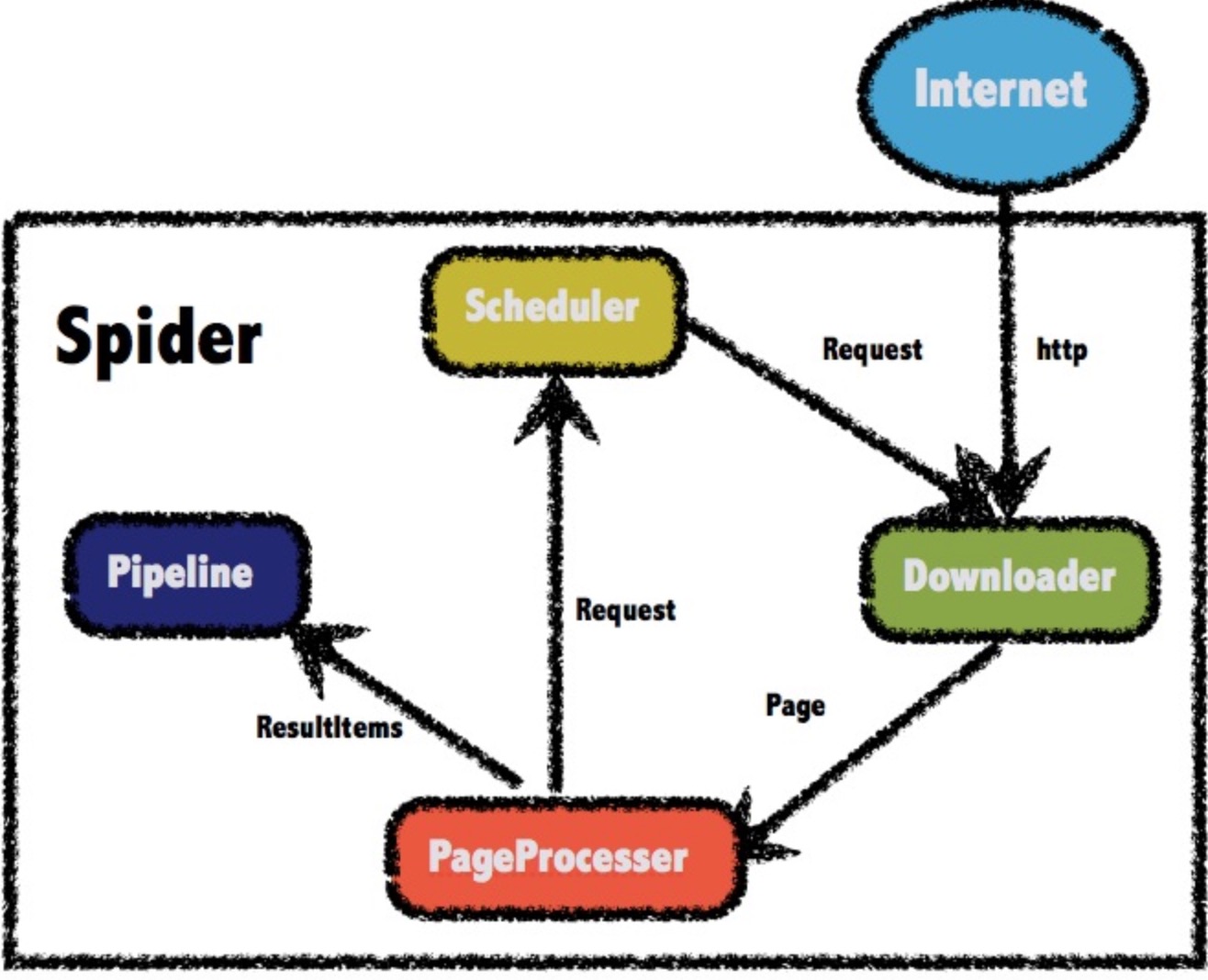
-
四大组件
组件 职责 DownloaderDownloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。 PageProcessorPageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。 SchedulerScheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。 PipelinePipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。 -
数据流转模型
Object 职责 Request对URL地址的一层封装,一个Request对应一个URL地址 Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。 ResultItemsResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。 - 爬虫控制核心引擎–Spider
Spider是WebMagic内部流程的核心。
Downloader、PageProcessor、Scheduler、Pipeline都是Spider的一个属性,这些属性是可以自由设置的,通过设置这个属性可以实现不同的功能。
Spider也是WebMagic操作的入口,它封装了爬虫的创建、启动、停止、多线程等功能。
